Why civil rights advocates should be involved in policy conversations about automated decision-making.
Around the country, automated systems are being used to inform crucial decisions about people’s lives. These systems, often referred to as “risk assessment tools,” are used to decide whether defendants will be released pretrial, whether to investigate allegations of child neglect, to predict which students might drop out of high school, and more.
The developers of these tools and government agencies that use them often claim that risk assessments will improve human decisions by using data. But risk assessment tools (and the data used to build them) are not just technical systems that exist in isolation — they are inherently intertwined with the policies and politics of the systems in which they operate, and they can reproduce the biases of those systems.
How do these kinds of algorithmic risk assessment tools affect people’s lives?
The Department of Justice used one of these tools, PATTERN, to inform decisions about whether incarcerated people would be released from prison to home confinement at the onset of the COVID-19 pandemic. PATTERN outputs “risk scores” — essentially numbers that estimate how likely it is a person will be rearrested or returned to custody after their release. Thresholds are then used to convert these scores into risk categories, so for example, a score below a certain number may be considered “low risk,” while scores at or above that number may be classified as “high risk,” and so on.

While PATTERN was not designed to assess risks related to a public health emergency (and hundreds of civil rights organizations opposed its use in this manner), the DOJ decided that only people whose risk scores were considered “minimum” should be prioritized for consideration for home confinement. But deciding who should be released from prison in the midst of a public health emergency is not just a question of mathematics. It is also fundamentally a question of policy.
How are risk assessment tools and policy decisions intertwined?
In a new research paper, we demonstrate that developers repeatedly bake policy decisions into the design of risk assessments under the guise of mathematical formalisms. We argue that this dynamic is a “framing trap” — where choices that should be made by policymakers, advocates, and those directly impacted by a risk assessment’s use are improperly hidden behind a veil of mathematical rigor.
In the case of PATTERN, a key metric, “Area Under the Curve” (AUC), is used to support claims about the tool’s predictive accuracy and to make arguments about the tool’s “racial neutrality.” Our research shows that AUC is often used in ways that are mathematically unsound or that hide or defer these questions of policy. In this example, AUC measures the probability that a formerly incarcerated person who was re-arrested or returned to custody was given a higher risk score by PATTERN than someone who did not return to prison. While AUC can tell us if a higher risk score is correlated with a higher chance of re-arrest, we argue that it is problematic to make broad claims about whether a tool is racially biased solely based on AUC values.
This metric also ignores the existence of the thresholds that create groupings like “high risk” and “low risk.” These groupings are crucial, and they are not neutral. When the DOJ used PATTERN to inform release decisions at the onset of the COVID-19 pandemic, they reportedly secretly altered the threshold that determines whether someone is classified as “minimum risk,” meaning far fewer people would qualify to be considered for release.
We argue that any choice about who gets classified into each of these groups represents an implicit policy judgement about the value of freedom and harms of incarceration. Though this change may have been framed as a decision based on data and mathematics, the DOJ essentially made a policy choice about the societal costs of releasing people to their homes and families relative to the costs of incarceration, arguably manipulating thresholds to effect policy decisions.
So, why should civil rights advocates care about this?
In our work assessing the impacts of automated systems, we see this dynamic repeatedly: government agencies rely on sloppy use of scientific concepts, such as using AUC as a seal of approval to justify the use of a model. Agencies or tool developers then set thresholds that determine whether people are kept in prison during a pandemic, whether they are jailed prior to trial, or whether their homes are entered without warrants.
Yet this threshold-setting and manipulation often happens behind closed doors. Mathematical rigor is often prioritized over the input of civil rights advocates and impacted communities, and civil rights advocates and impacted communities are routinely excluded from crucial conversations about how these tools are designed or whether they should be designed at all. Ultimately, this veiling of policy with mathematics has grave consequences for our ability to demand accountability from those who seek to deploy risk assessments.
How can we ensure that government agencies and other decision-makers are held accountable for the potential harm that risk assessment tools may cause?
We must insist that tool designers and governments lift the veil on the critical policy decisions embedded in these tools — from the data sets used to develop these tools, to what risks the tools assess, to how the tools ultimately box people into risk categories. This is especially true for criminal and civil defense attorneys whose clients face life-altering consequences from being labeled “too risky.” Data scientists and other experts must help communities cut through the technical language of tool designers to lay bare their policy implications. Better yet, advocates and impacted communities must insist on a seat at the table to make threshold and other decisions that represent implicit or explicit policymaking in the creation of risk assessments.
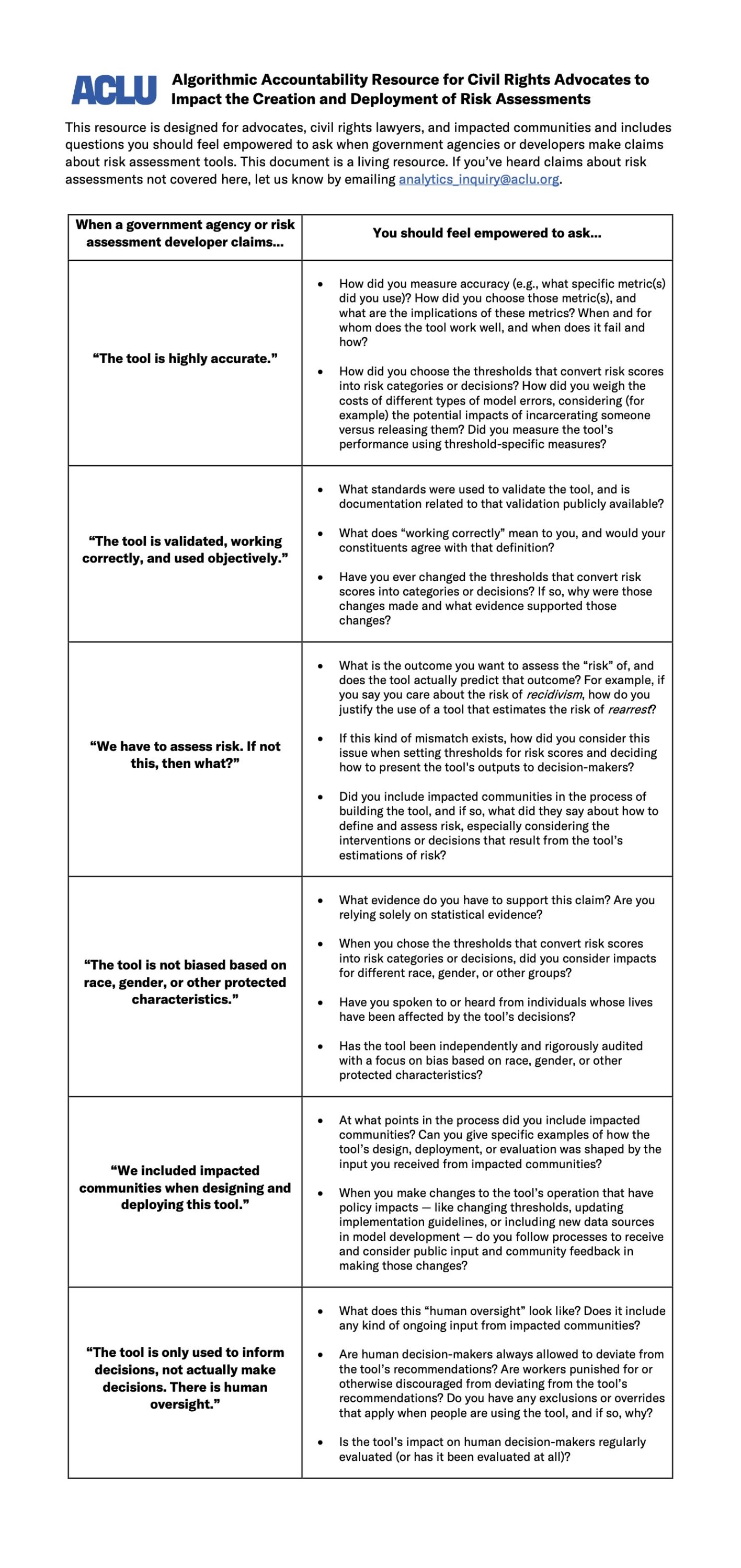
To push for this change, we’ve created a resource for advocates, lawyers, and impacted communities, including questions you should feel empowered to ask when government agencies or developers make claims about risk assessment tools: